
编者按
本公众号将定期推送人工智能安全相关的顶刊编译。本期顶刊编译,我们分别追踪了《专家系统应用》(Expert Systems with Applications)以及《国际众智科学期刊》(International Journal of Crowd Science)中的两篇文章,具体如下:
1、Artificial Intelligence Trust, Risk and Security Management (AI TRiSM):Frameworks, applications, challenges and future research directions
人工智能信任、风险和安全管理(AI TRiSM):框架、应用、挑战和未来的研究方向
引用:Habbal A, Ali M K, Abuzaraida M A. Artificial Intelligence Trust, risk and security management (AI trism): Frameworks, applications, challenges and future research directions[J]. Expert Systems with Applications, 2024, 240: 122442.
2、Fairness in Design: A Framework for Facilitating Ethical Artificial Intelligence Designs
设计公平性:促进合乎道德的人工智能设计的框架
引用:Zhang J, Shu Y, Yu H. Fairness in design: a framework for facilitating ethical artificial intelligence designs[J]. International Journal of Crowd Science, 2023, 7(1): 32-39.

《人工智能信任、风险和安全管理(AI TRiSM):框架、应用、挑战和未来的研究方向》


提要


主要内容


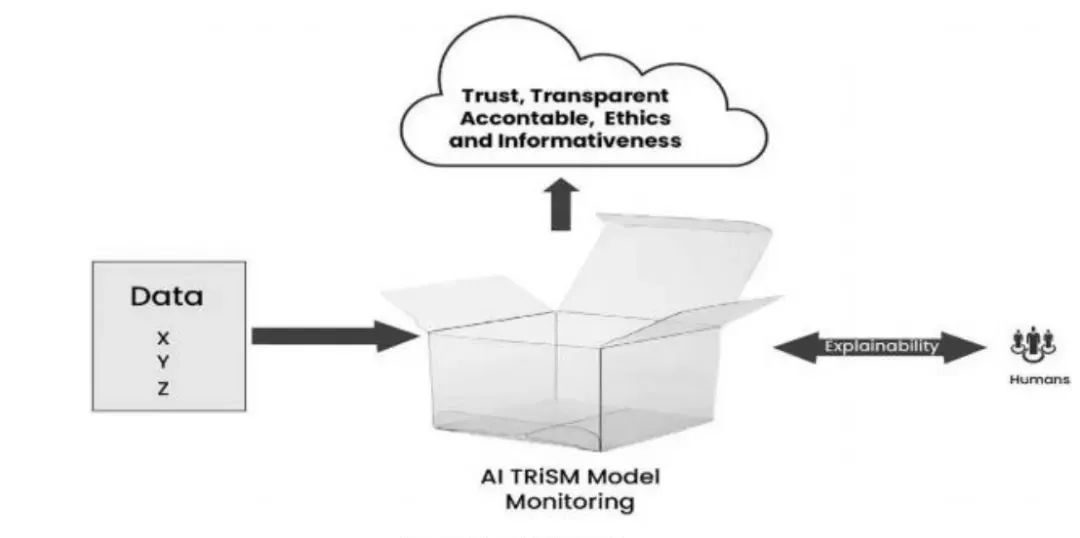
人工智能模型面临用户信任缺失问题,主要源于透明度和道德相关问题,其决策过程复杂难以理解,这对问责制构成挑战。实现模型监控和可解释性可确保模型功能正常且无偏差,有助于理解模型操作、提高透明度并建立信任。通过可解释性 AI TRiSM模型监控操作,能为用户提供透明、信任和信息,如下图。




总结

《设计公平性:促进合乎道德的人工智能设计的框架》


提要


主要内容
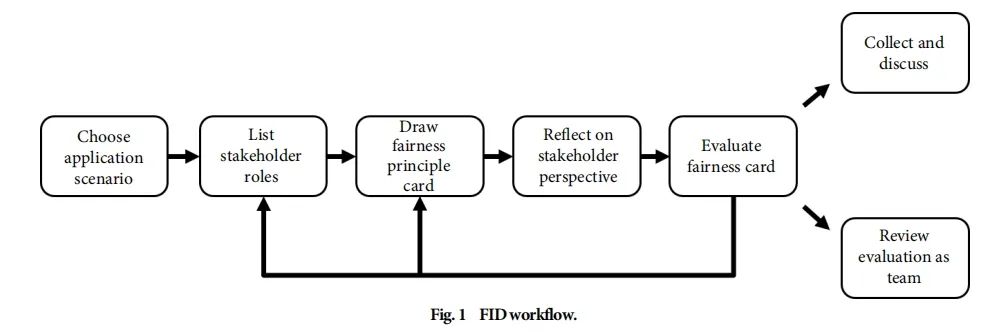
图1 FID工作流程
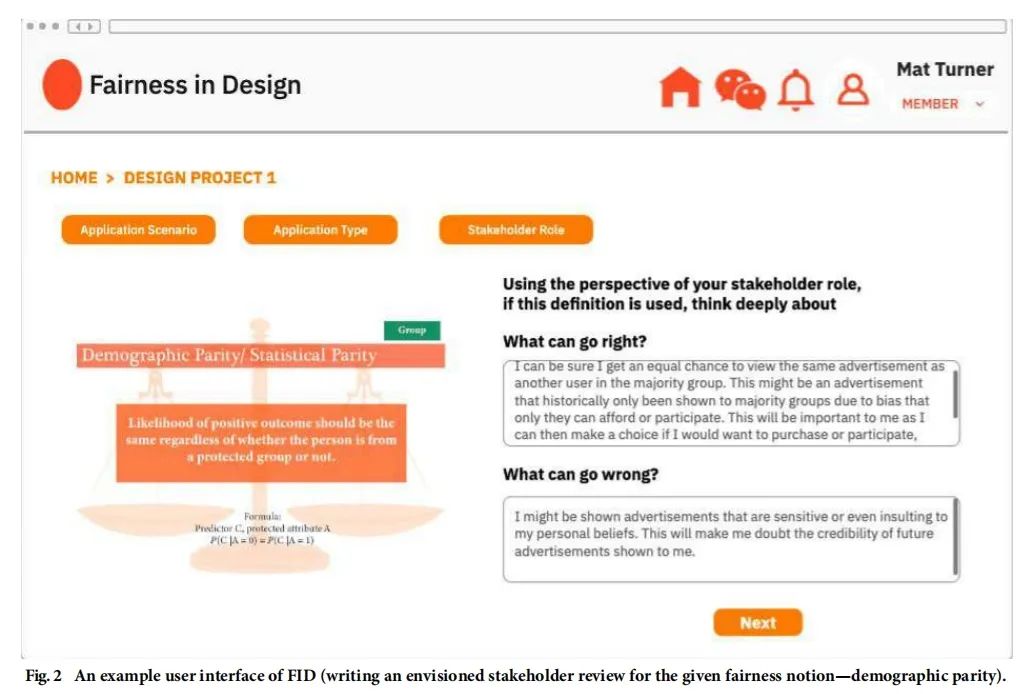
图2所示的FID 的用户界面示例呈现了用户在步骤 3 的操作,即从所采用的利益相关者视角撰写设想审查

图3参与者的人口统计数据
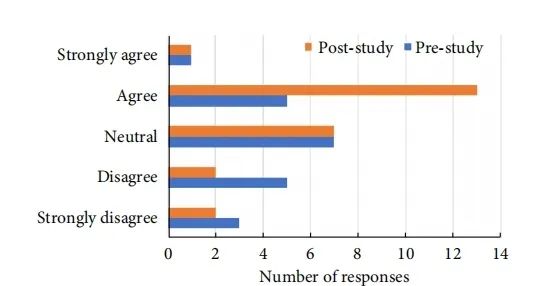
图4参与者在使用 FID 前后做出与公平性相关的设计决策的自我报告能力
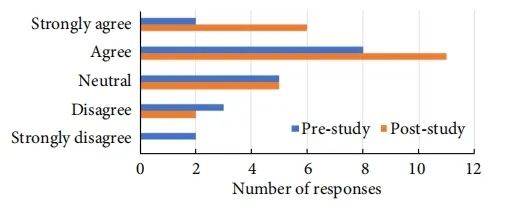
图5参与者在使用 FID 之前和之后自我报告的浮出水面公平问题的能力
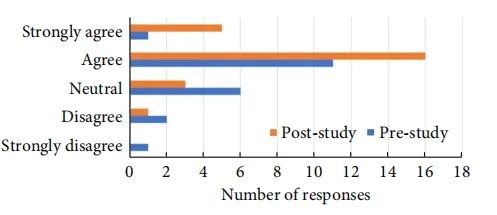
图6参与者在使用 FID 前后自我报告的从利益相关者的角度思考的能力


总结
END